作为一个iOS初学Django服务端,并为多个小程序提供稳定的服务
python的web框架中有Django和Flask,选择Django的原因就是生态完善,工具齐全。缺点就是臃肿、沉重。
Flask是微框架,很多东西都是插件化,如果不熟悉服务端开发的话上手起来并不容易,很多东西都要自己造轮子,定制化强。
所以最终选择python==3.6.8和Django==2.1.10
Django
REST
个人觉得是个规范,可以根据业务需求具体遵守。
Environment
环境区分,使用环境变量控制:"DJANGO_SETTINGS_MODULE": "project_name.settings_debug"
- settings: 基础配置
- settings_debug:本地调试配置
- settings_test:测试环境配置
- settings_master:正式环境配置
Mysql
- mysqlclient:Django默认使用
使用了本地的mysqlclient的头文件,由于需要使用utf8mb4(5.5.3开始支持),而当前部署的服务器的mysql-client版本过低(5.1.73),所以无法使用。
- PyMySQL:由python重写,但是从Django2.2开始不支持
utf8mb4无法设置
1 | # 当本地mysql-client版本过低时,使用'charset': 'utf8mb4'无效时 |
1 | # requirements.txt |
自定义数据库路由
线上环境不允许ORM建表,所以Django的Admin表从测试环境读取
由此可以实现不同的applabel读取不同的数据库
1 | # settings.py |
Logging
日志记录
1 | # 自定义日志记录样式 |
propagate参数显得尤为重要
Sentry
日志错误处理,早期的Raven使用方式不建议
1 | # settings.py |
Django RQ
相当于将代码序列化到redis中,然后由任意的一台服务器获取执行,序列化中不能包含非基本对象。
Redis Queue
1 | # settings.py |
自定义RQ Workder,目的是为了添加自定义的Sentry(否则走的是RQ自定义的Sentry)
1 | import rq |
Gunicorn
提高Django的并发,创建多个worker(即多个unix进程)
1 | # Run gunicorn with config |
Gevent:协程框架
协程:使用协程进行io异步提高并发
Config详情
1 | # gunicorn.conf.py |
Supervisor
进程管理,管理Gunicorn和RQ进程,检测异常退出,会自动重启。
Config
1 | ; Sample supervisor config file. |
1 | # 启动 |
Nginx
由于历史原因,项目由PHP作为V1版本开发,V2版本全部迁移到Django,所以采用Nginx作为端口转发
Fabric
脚本作为CI/CD工具,更新服务器代码并重启服务器,好处是可以手动重启服务器,缺点是不自动化。
AB测试
被测试服务器信息


单台服务器内网测试
1 | # gunicorn.conf.py |
直接返回JSON,无任何操作
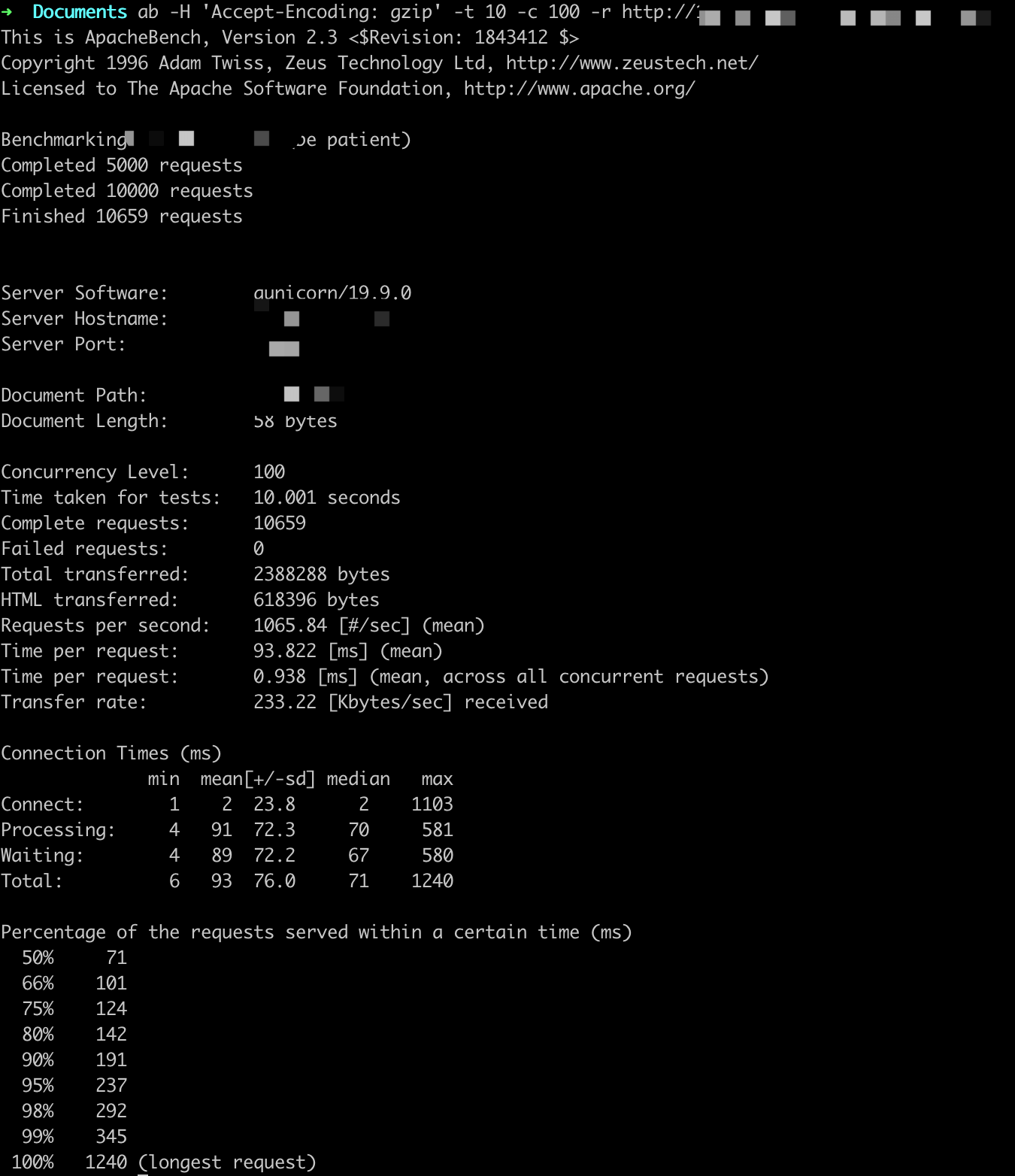
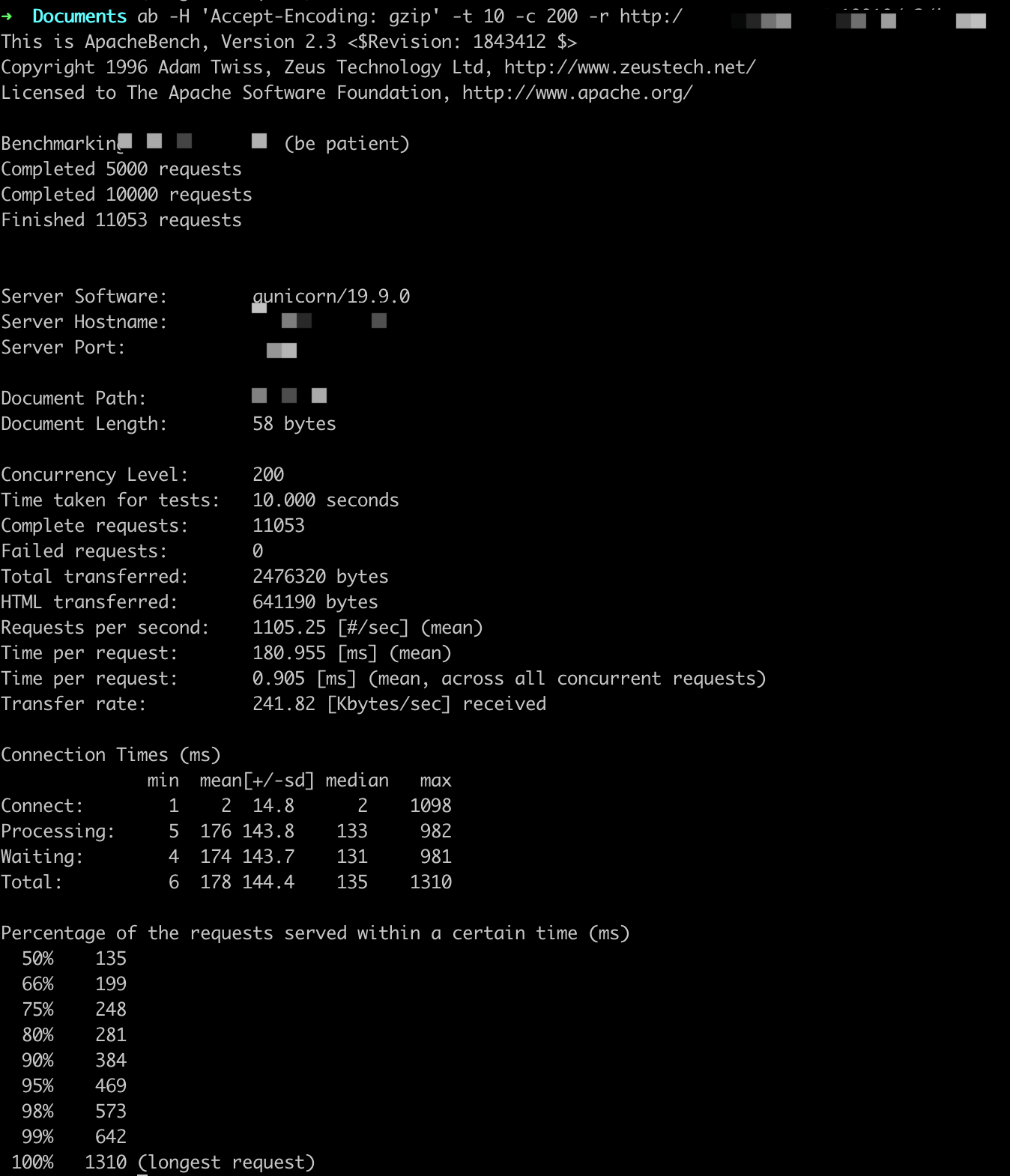
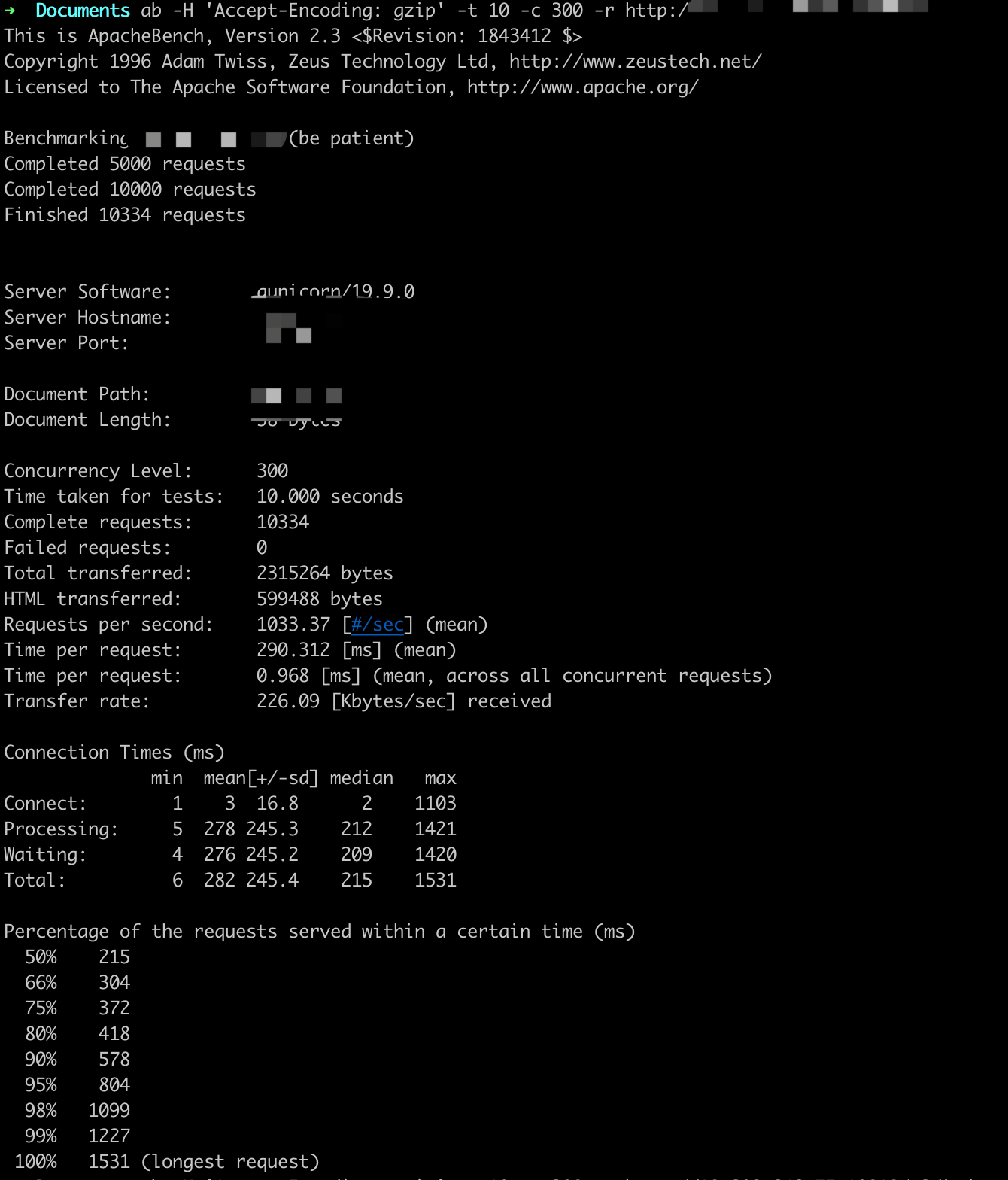
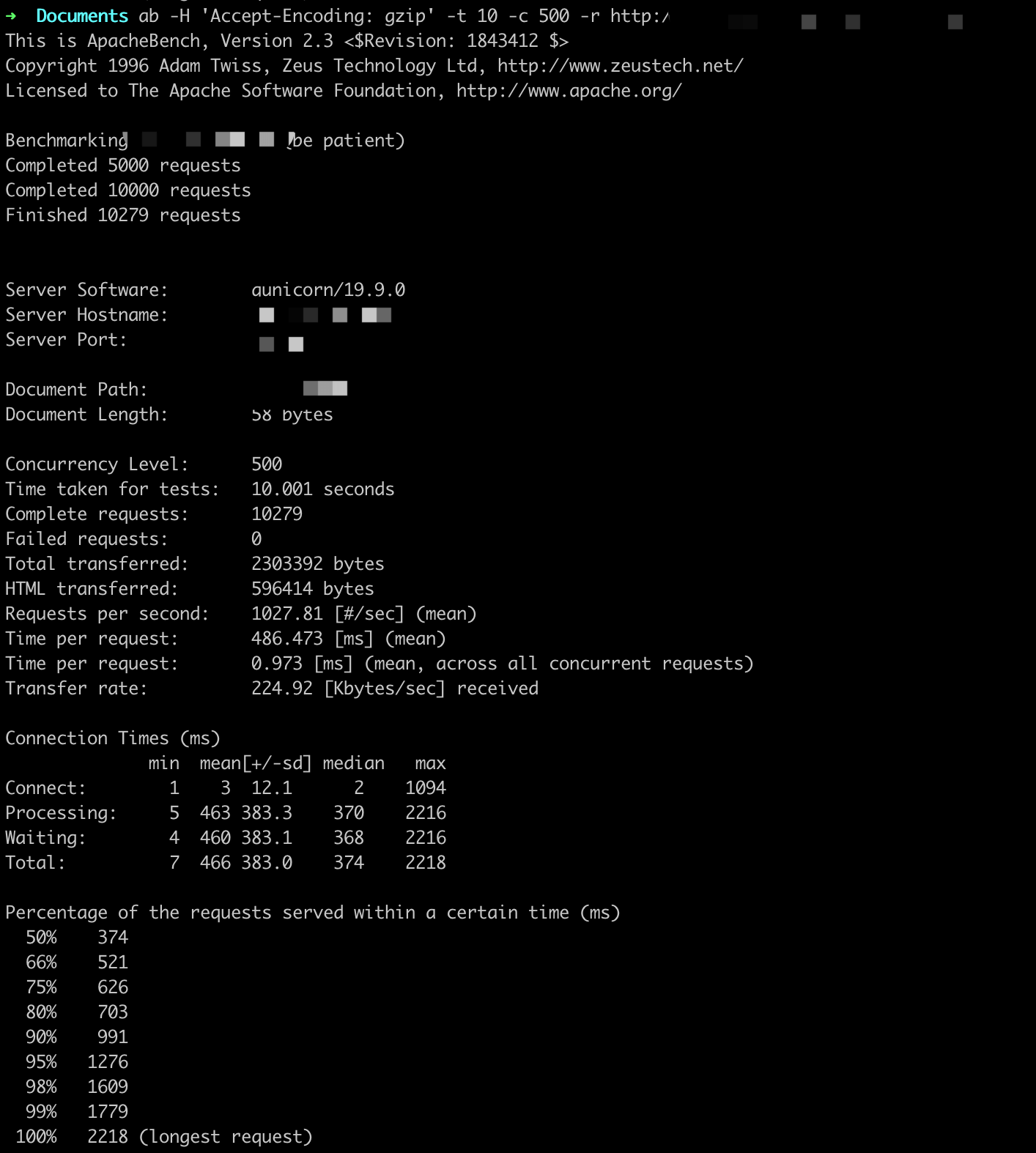
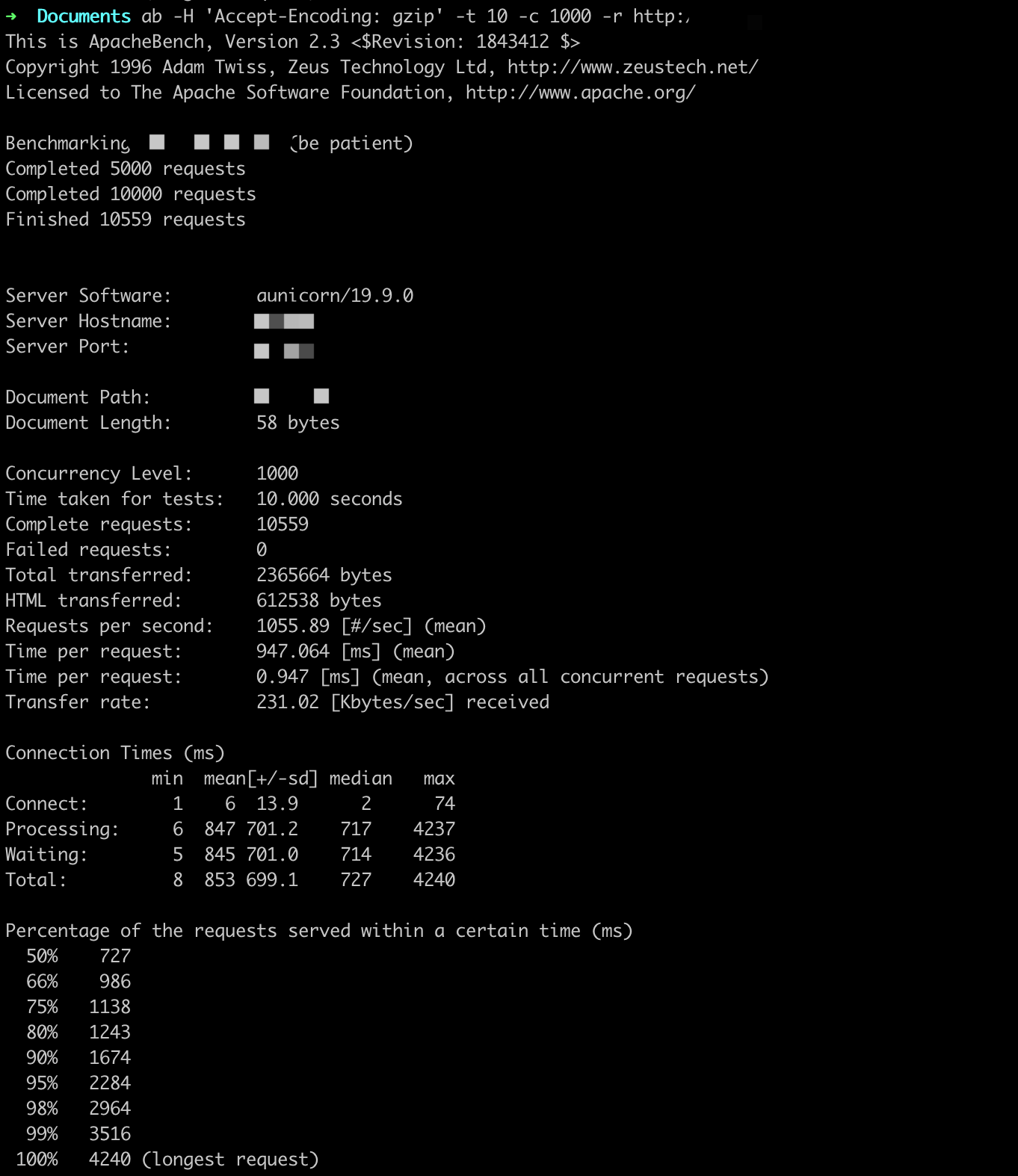
参数设置:-t 10 -c X
ab -H 'Accept-Encoding: gzip' -t 10 -c X -r http://
QPS基本在1000以上,随着并发用户的量变多,平均用户等待时间变长。
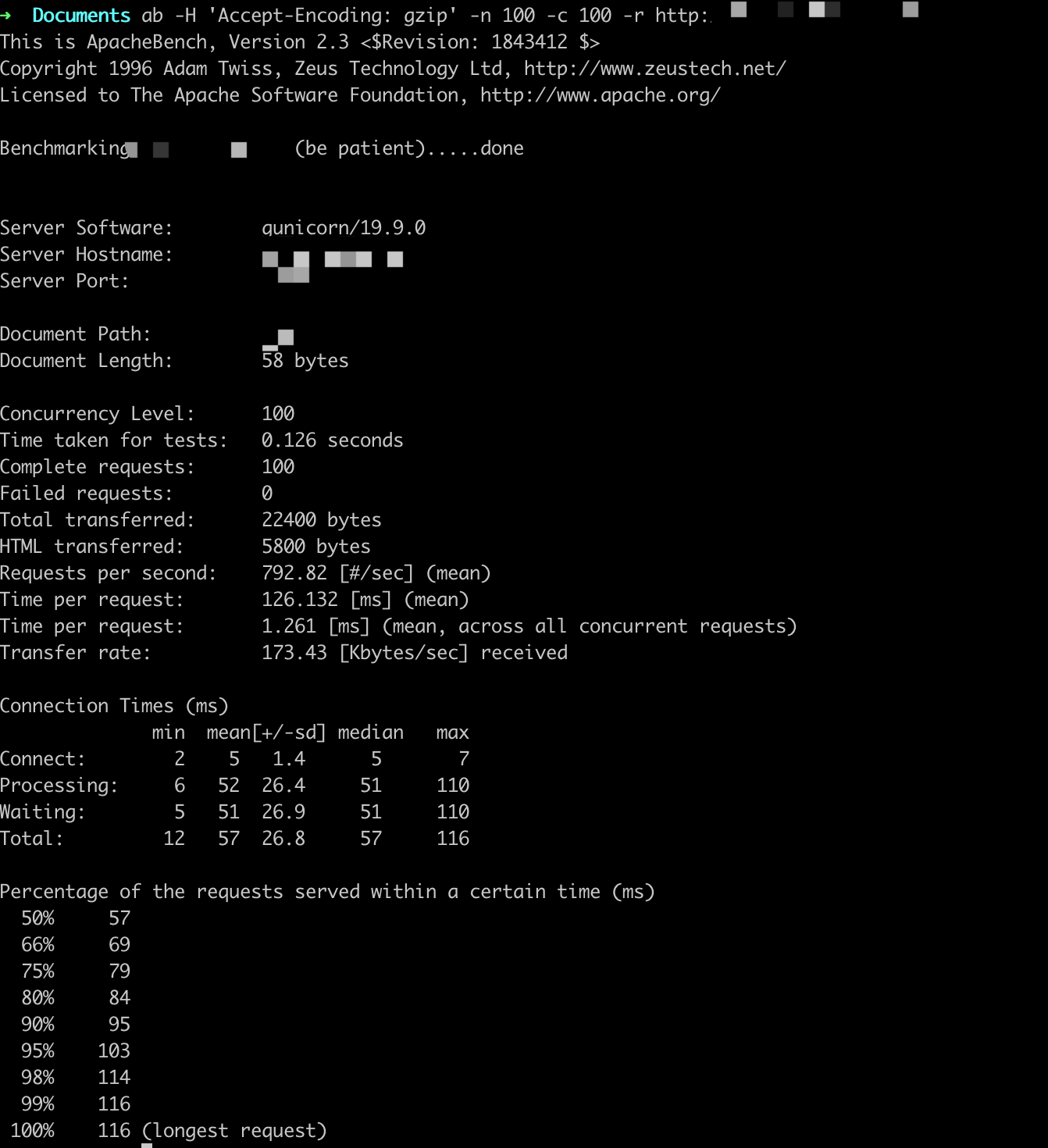
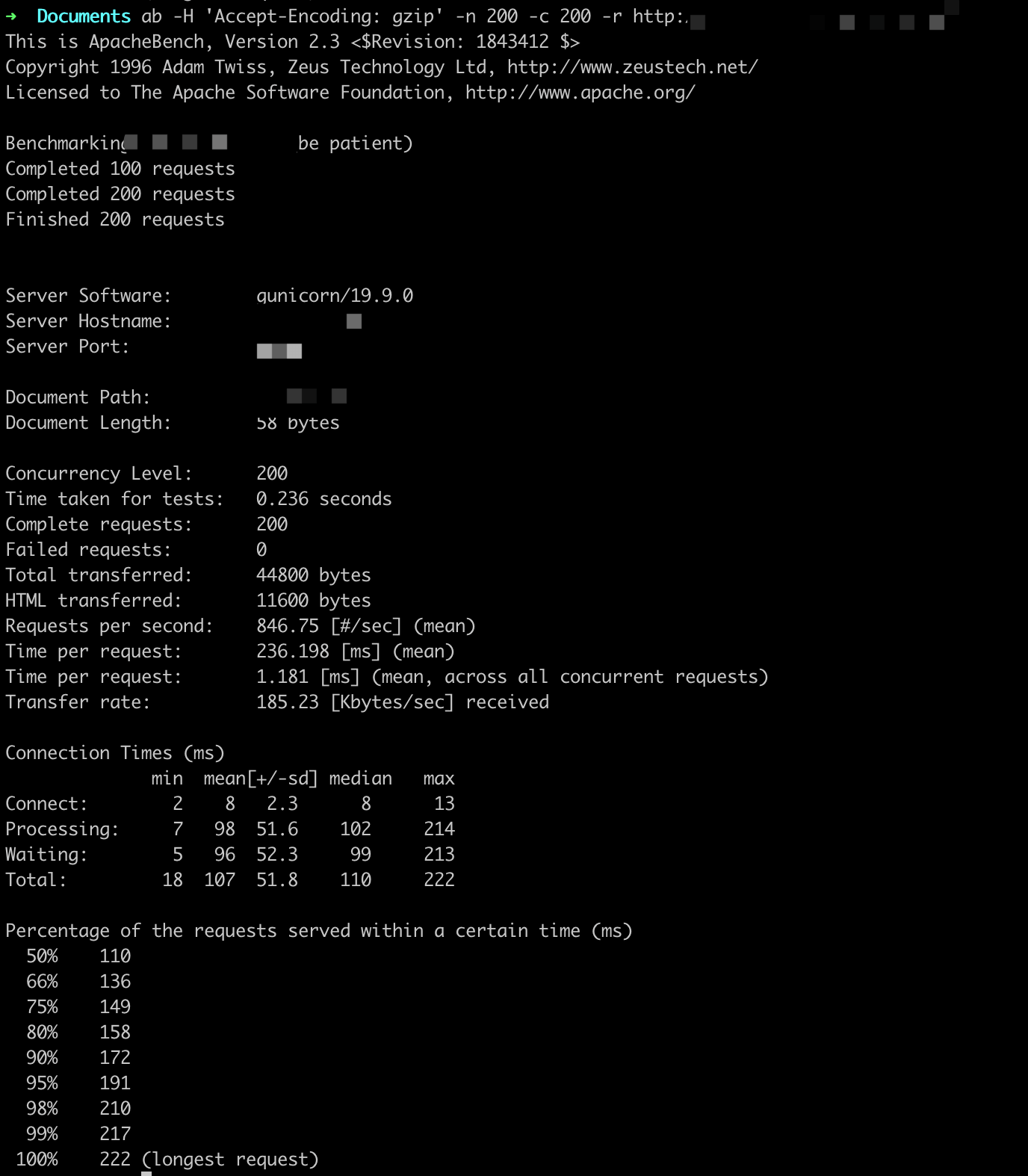
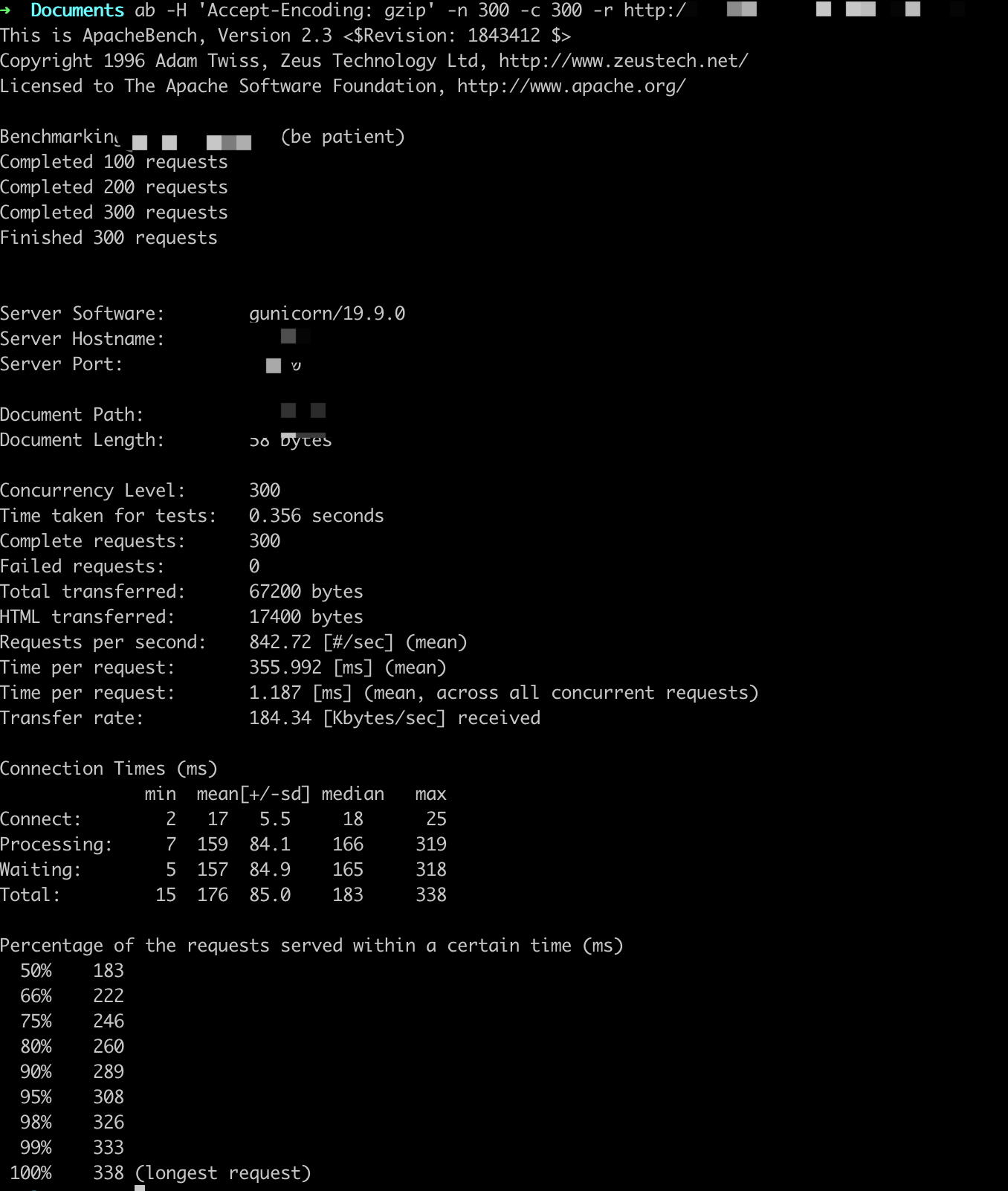
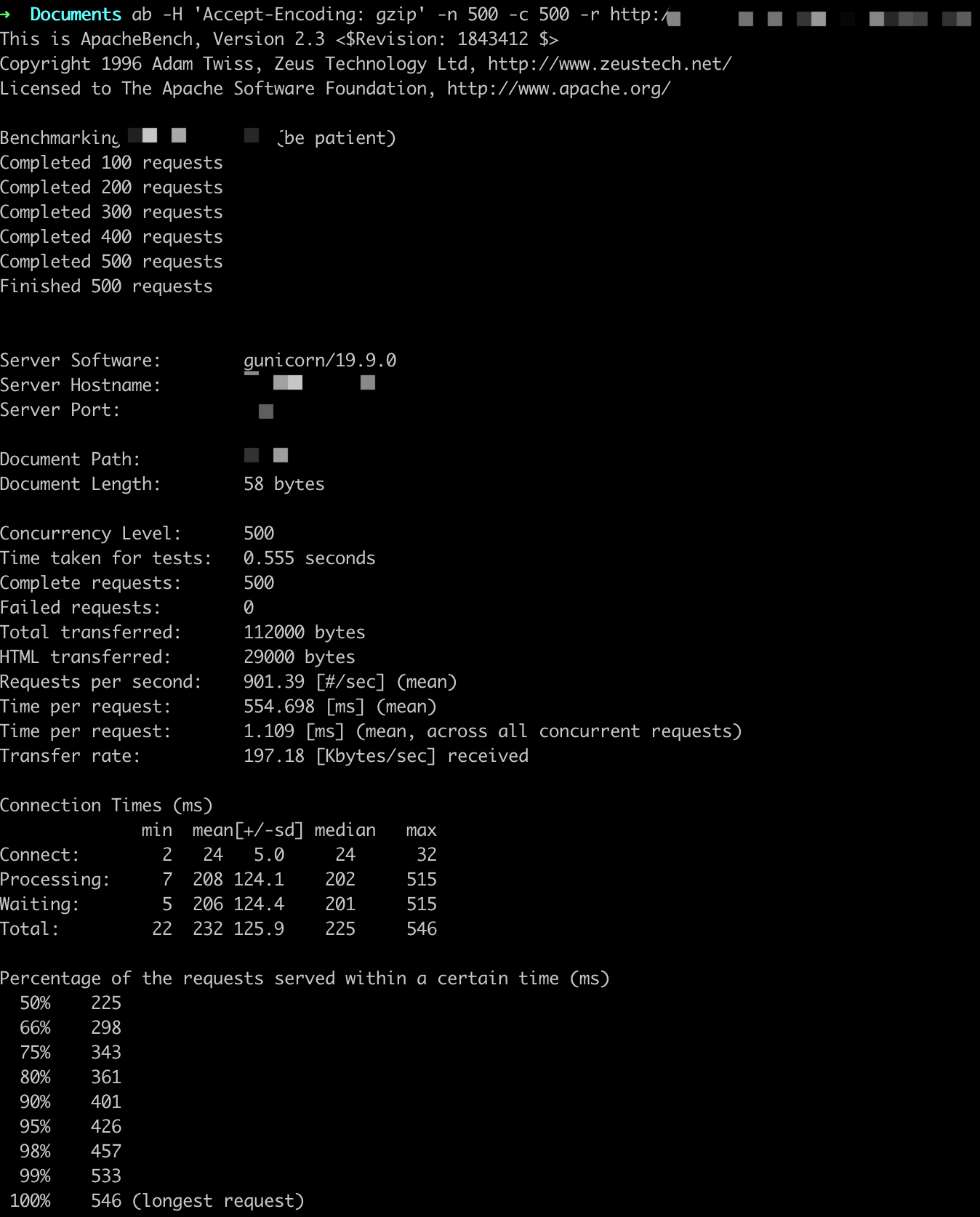
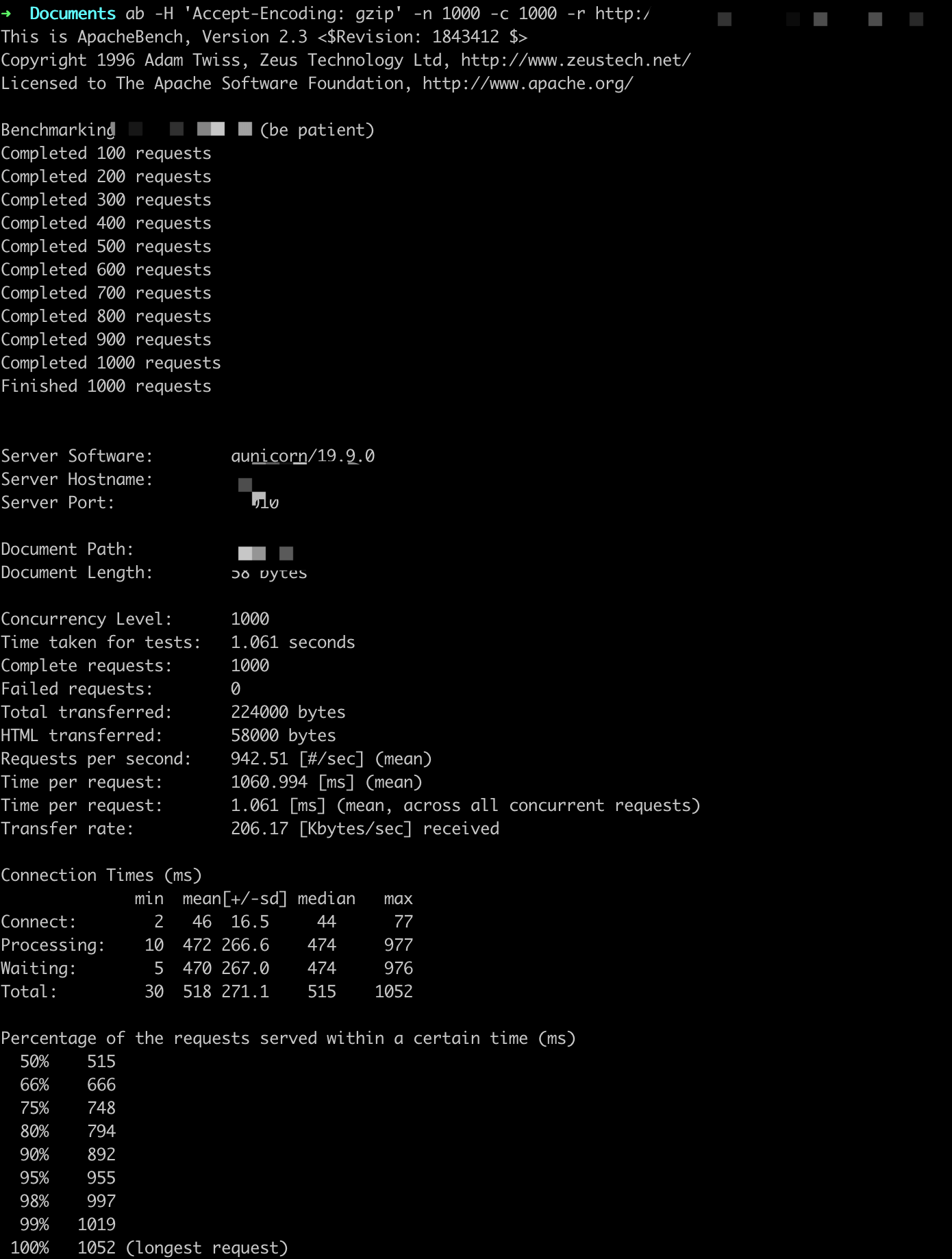
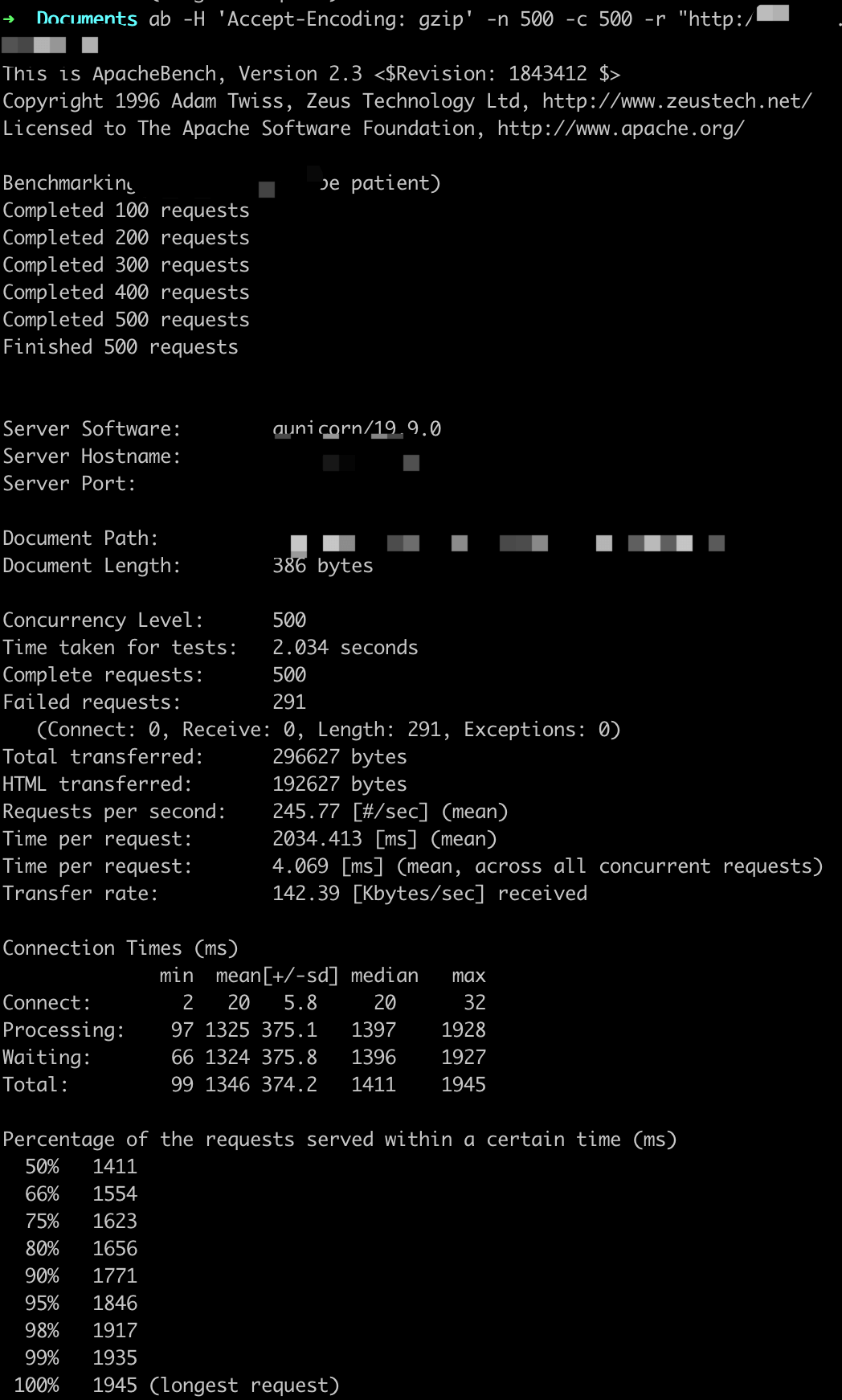
参数设置:-n X -c X
ab -H 'Accept-Encoding: gzip' -n X -c X -r http://
QPS基本在800以上,随着并发用户的量变多,平均用户等待时间变长。
数据库查询单条数据、Redis get数据,返回JSON
参数设置:-t 10 -c X
ab -H 'Accept-Encoding: gzip' -t 10 -c X -r http://
QPS基本在250以上,随着并发用户的量变多,平均用户等待时间变长。
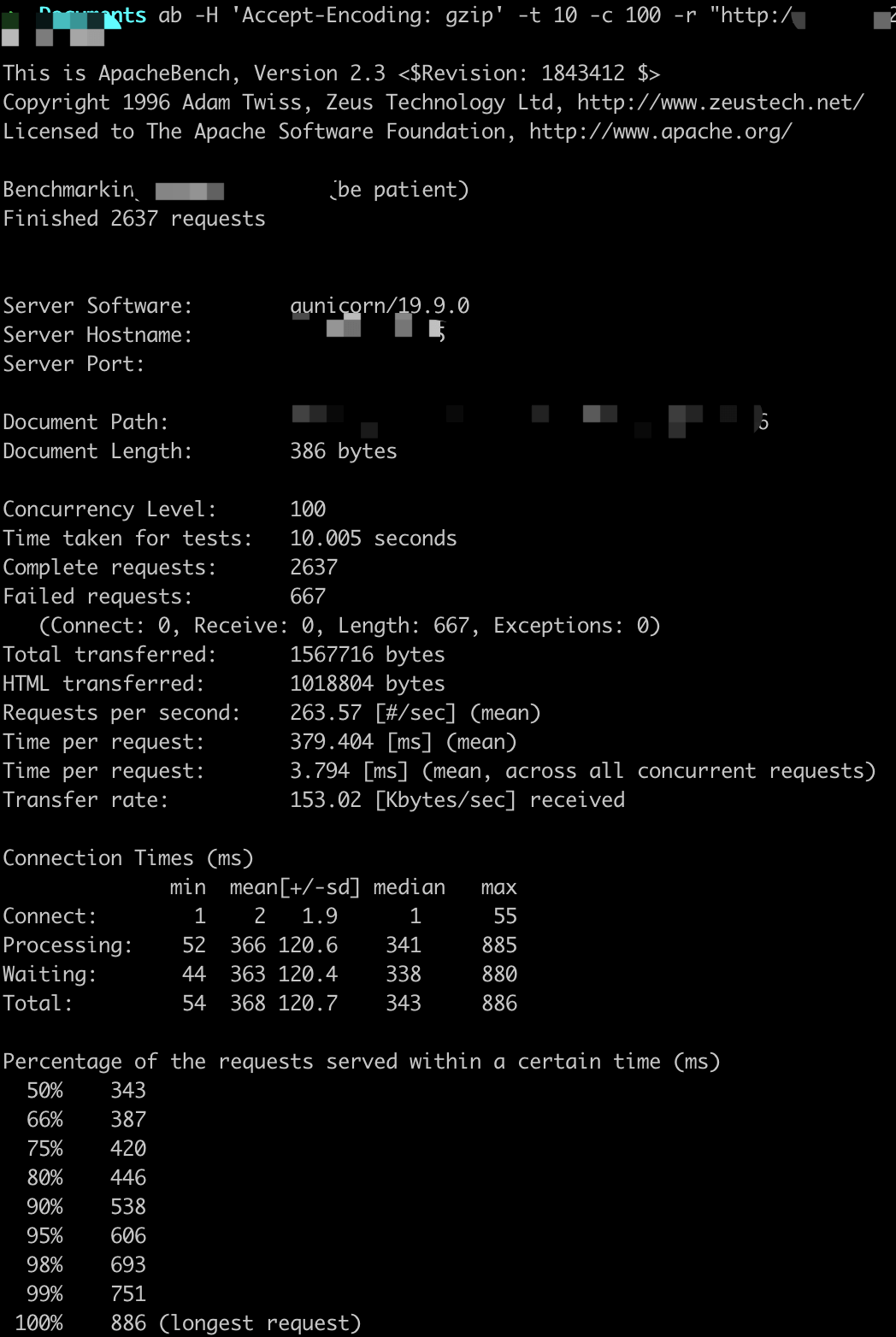
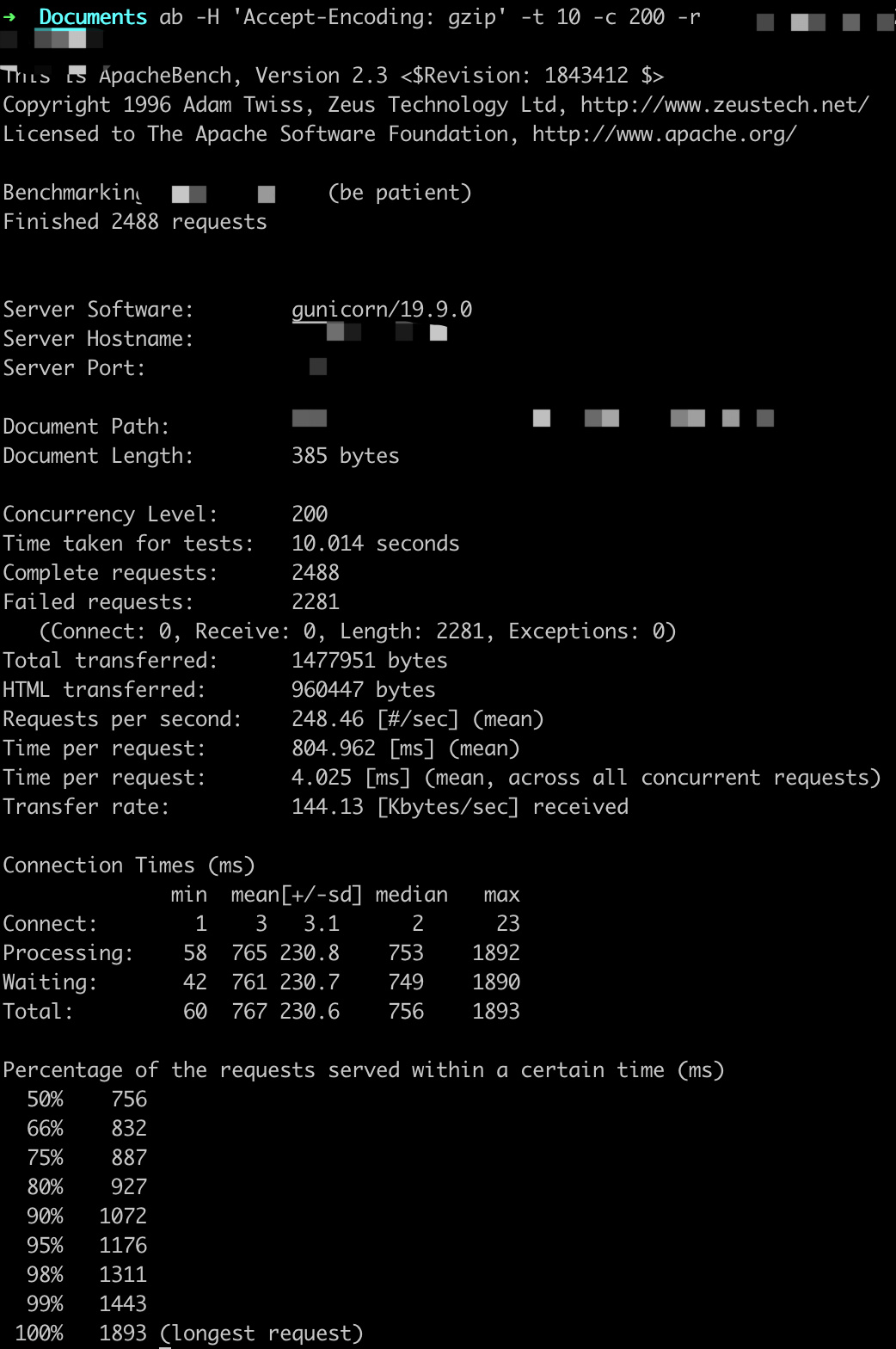
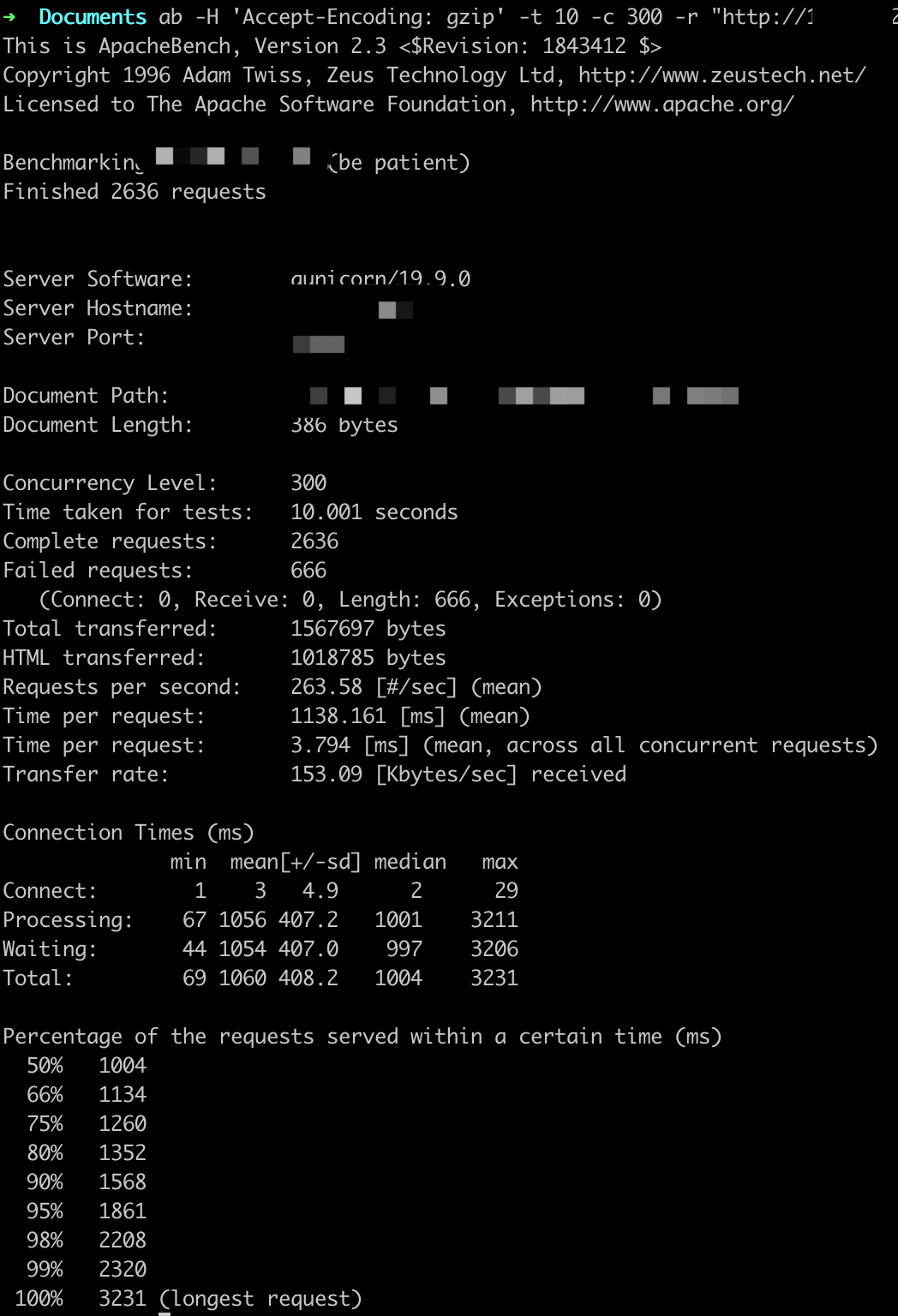
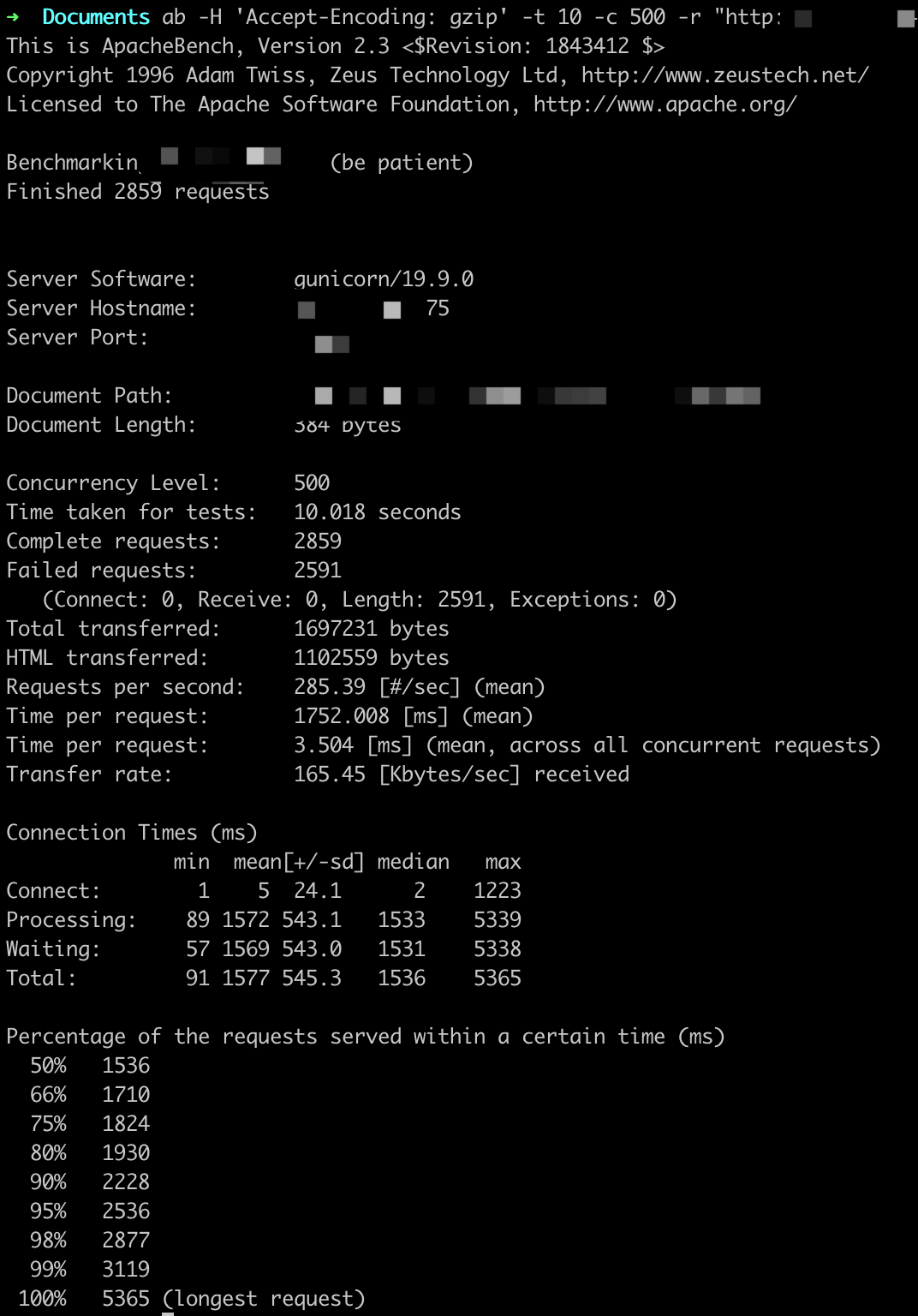
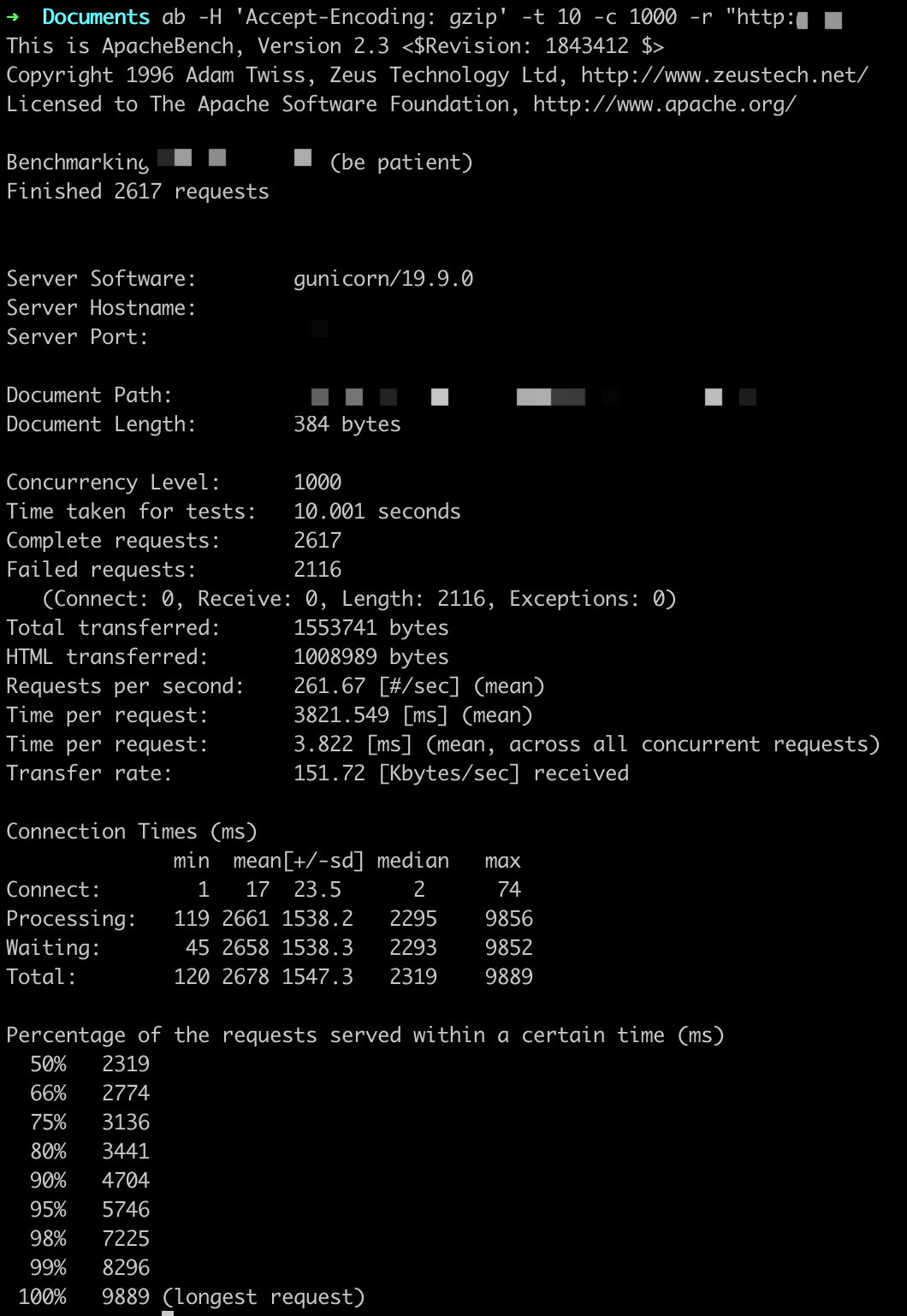
这里虽然显示很多错误,但是Gunicorn日志中返回的都是200,原因不详
参数设置:-n X -c X
ab -H 'Accept-Encoding: gzip' -n X -c X -r http://
QPS基本在250以上,随着并发用户的量变多,平均用户等待时间变长。
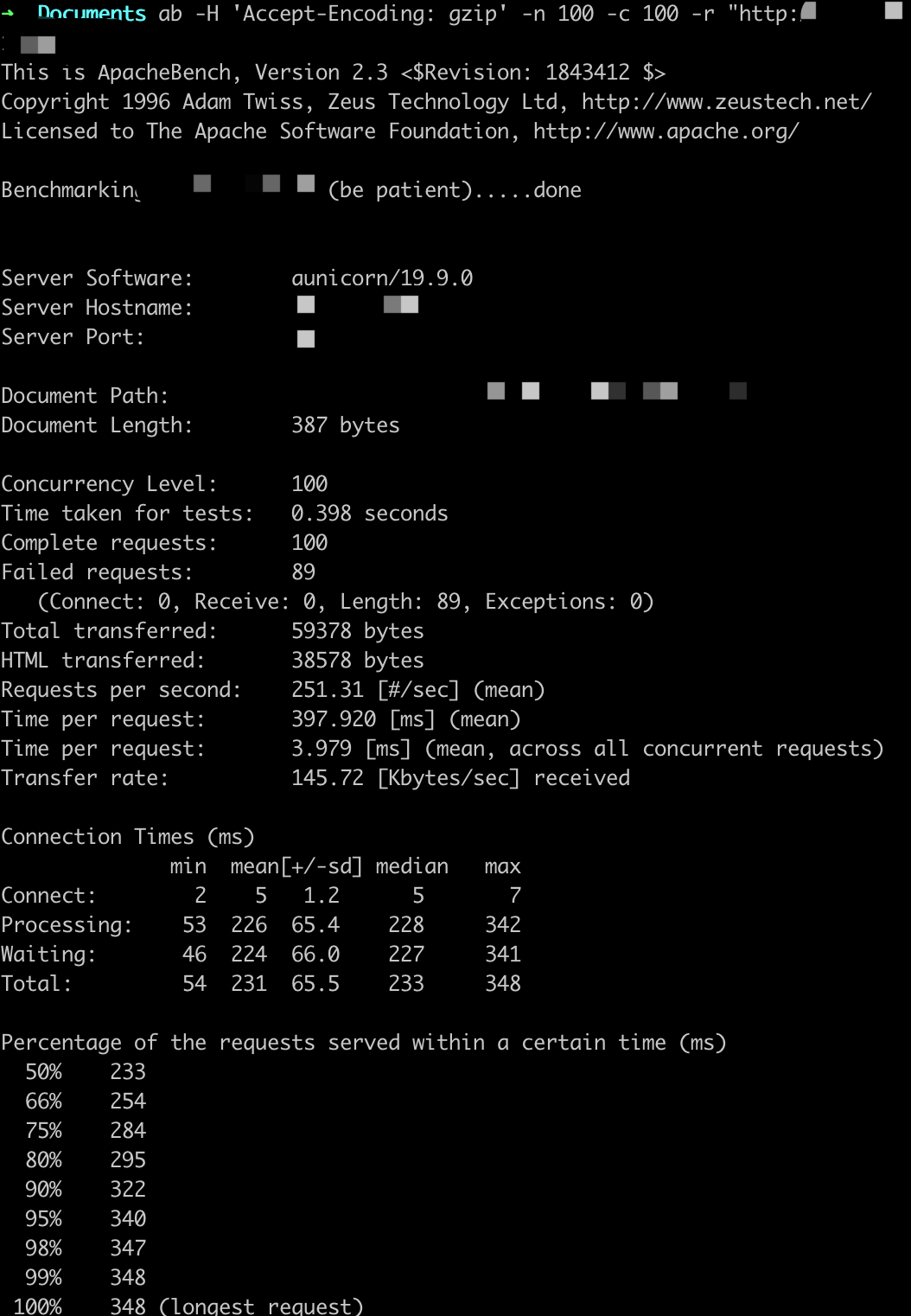
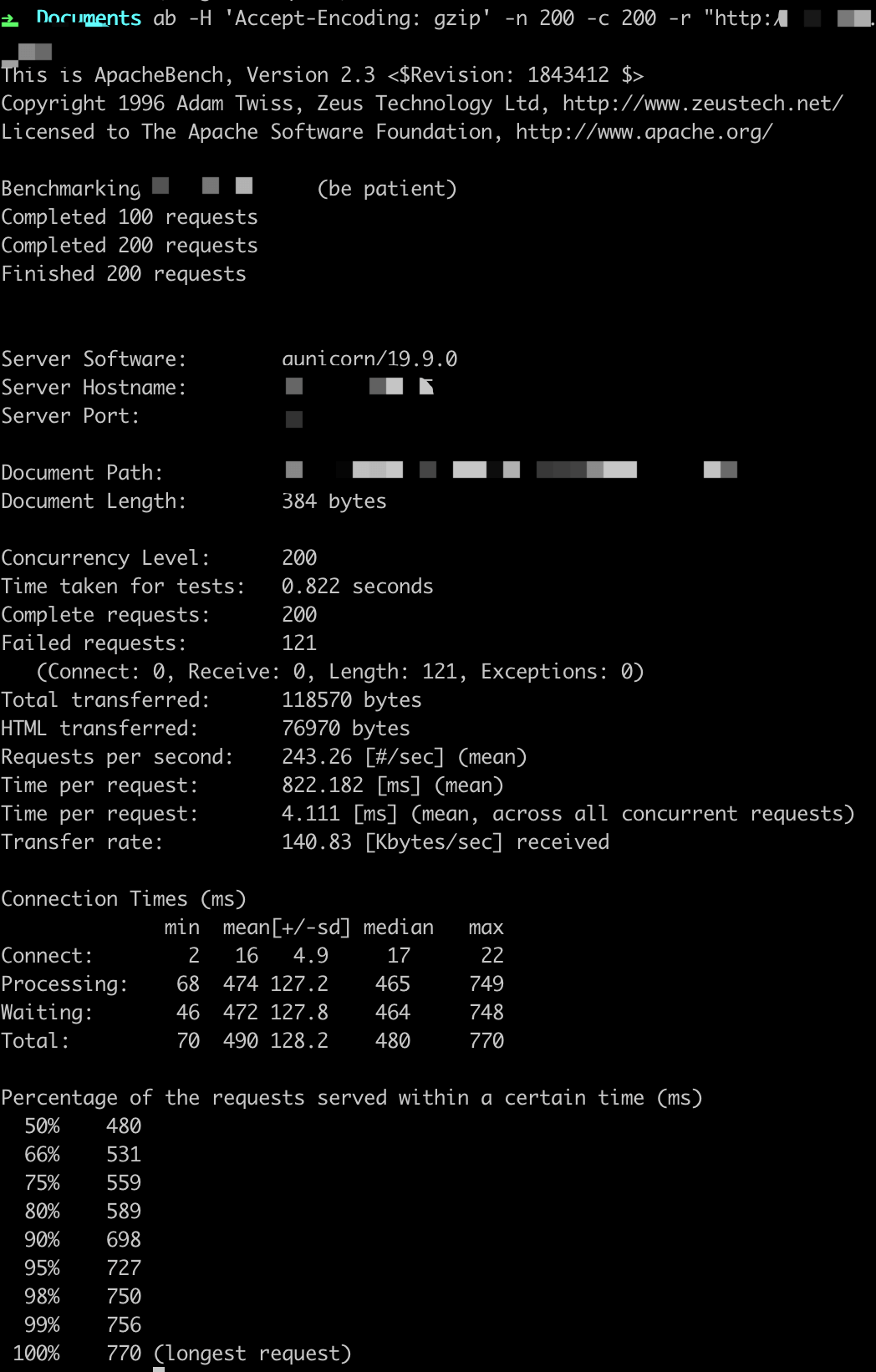
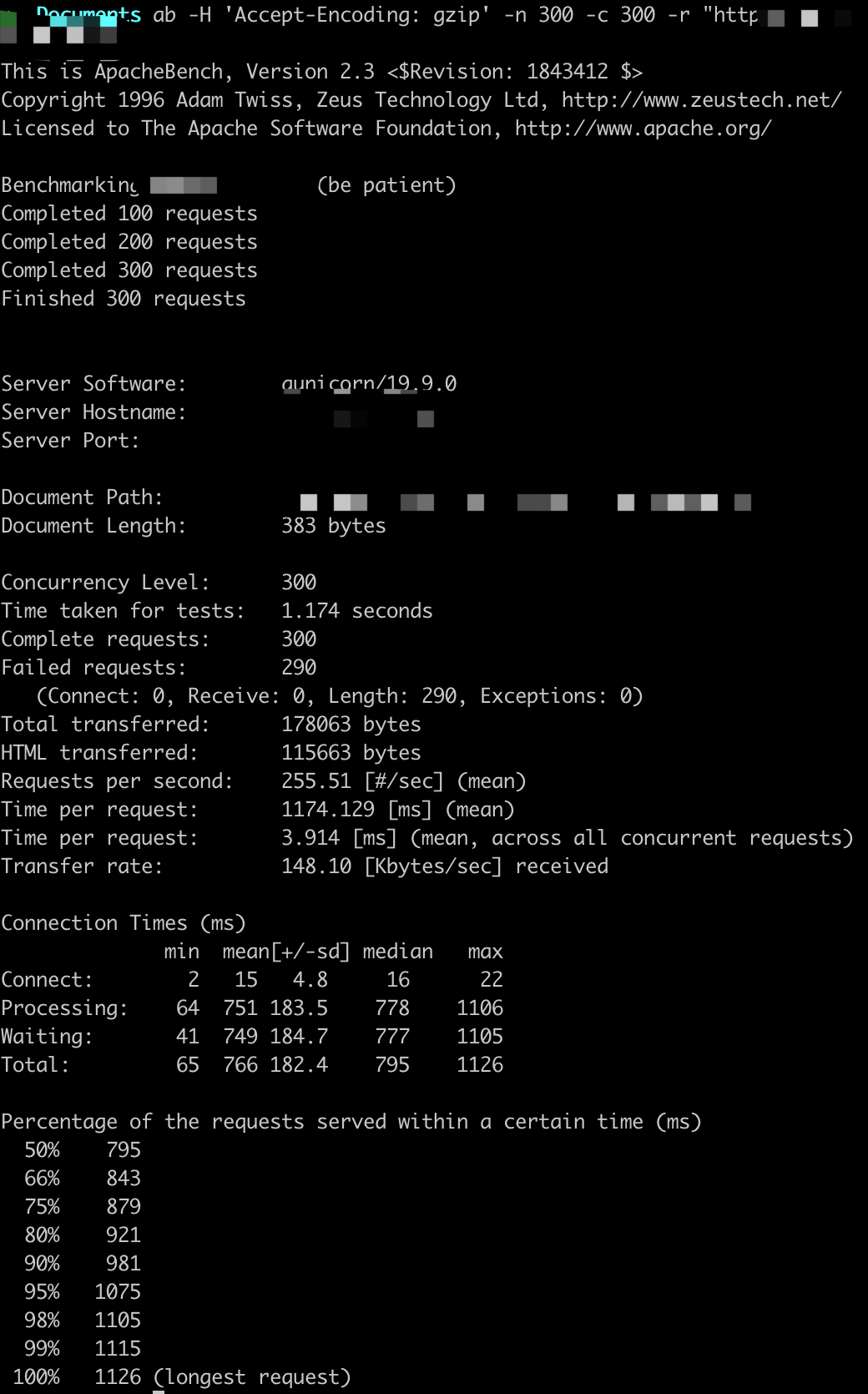
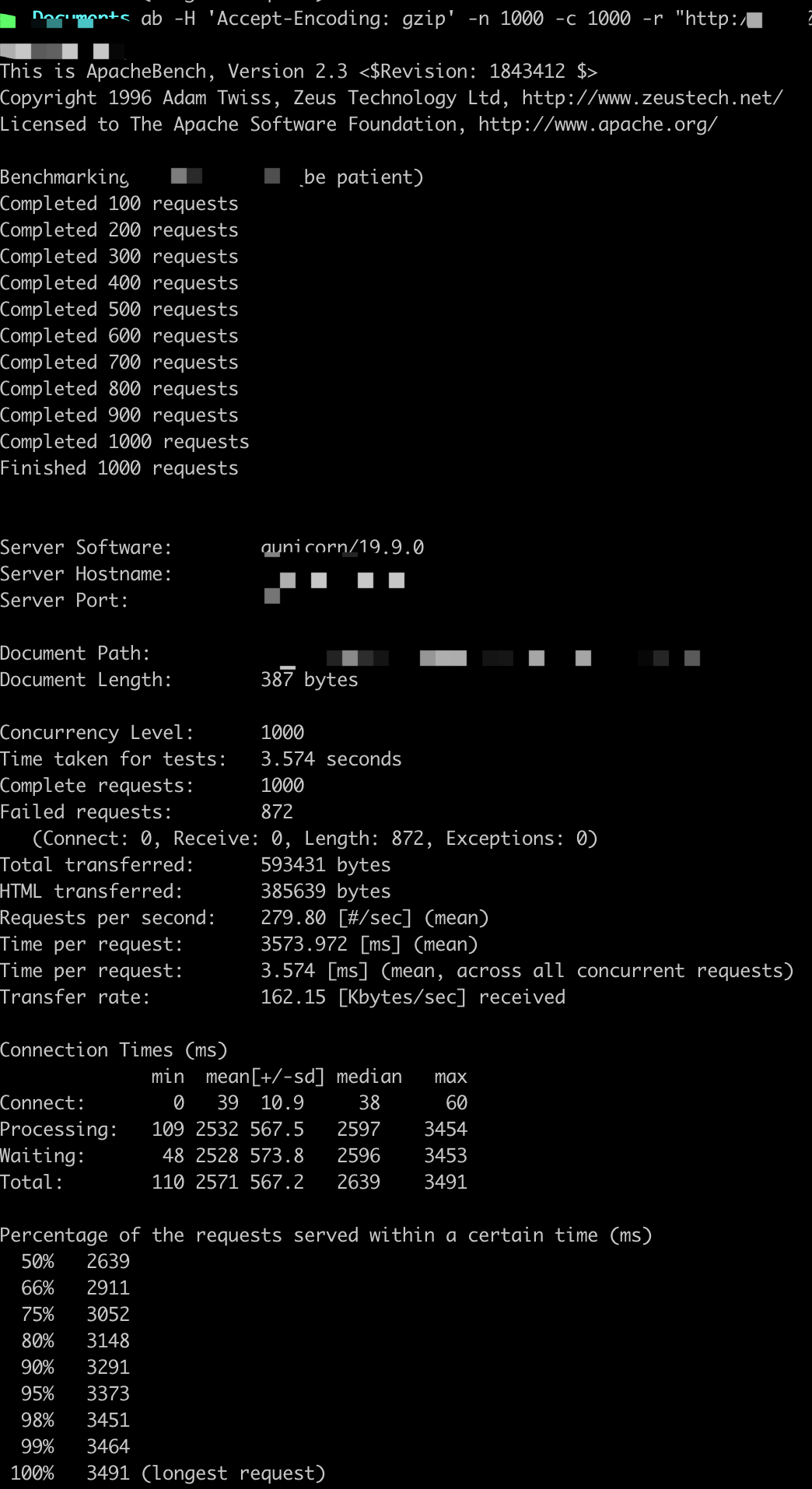
这里虽然显示很多错误,但是Gunicorn日志中返回的都是200,原因不详
LVS负载(轮询),Nginx,4台服务器
1 | # gunicorn.conf.py |
数据库查询单条数据、Redis get数据,返回JSON
参数设置:-t 10 -c 1000
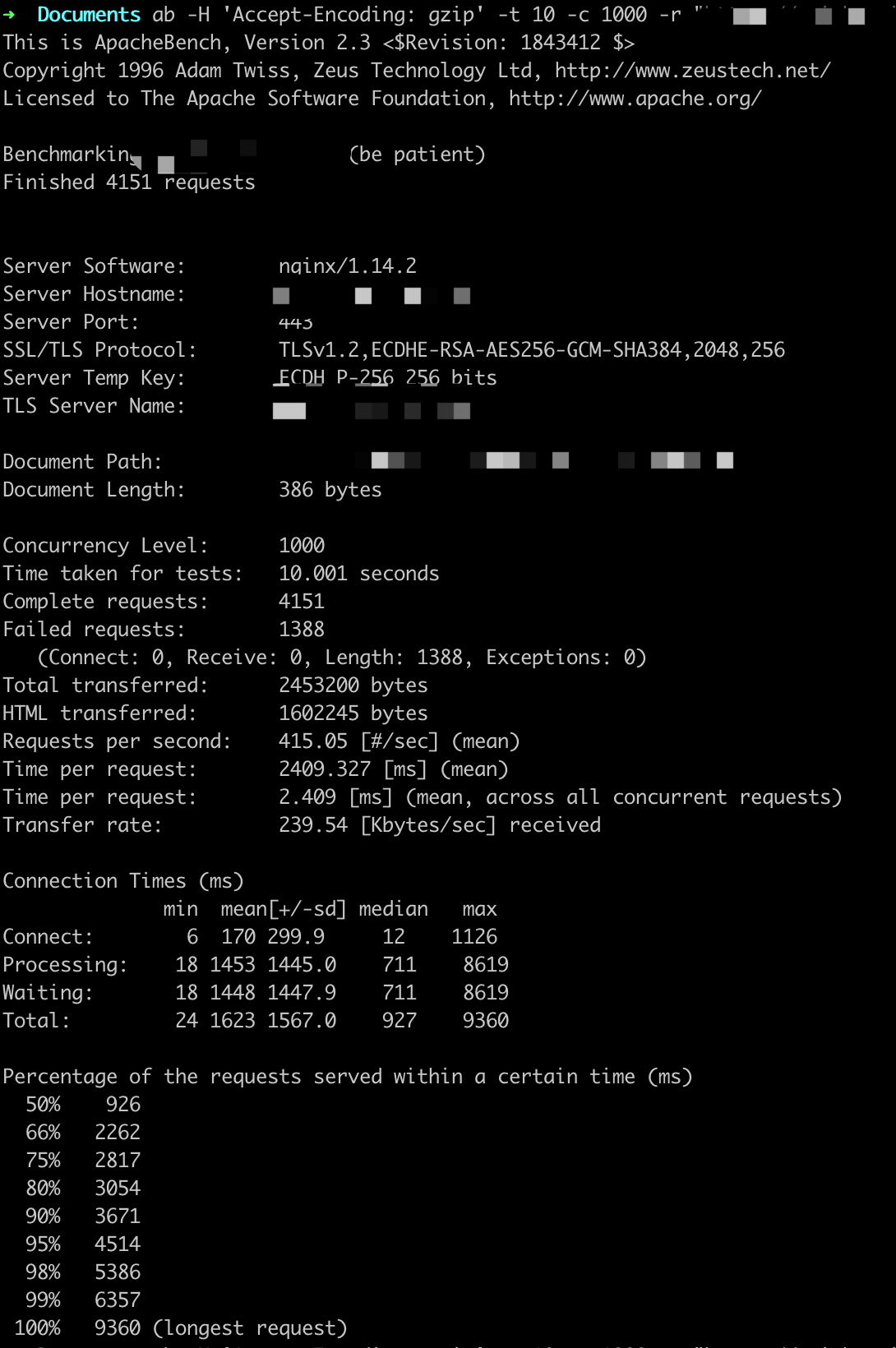
思考
项目中并未使用微服务架构,也并没有使用docker进行部署,也未使用k8s,可以说是最小的实践方式。
用最简单的方式测试想法是否可以。